The Librarian's Dilemma: Why Your RAG System Lies (And How Knowledge Graphs Can Fix It)
In my last post From Messy Stories to Mission Statements, I mentioned using Relevance AI, a low-code platform for prototyping AI agent workflows. While creating that demo, I had hit a wall with their customer service chatbot. When I asked how to format an API request to trigger an agent, it fed me a series of incorrect examples. My coding co-pilot and I then spent the next ninety minutes untangling a mess of API Keys, Authorization Tokens, and Region Codes before we finally discovered the correct format.

An example of the incorrect API request format that sent us down a 90-minute rabbit hole. A common symptom of a flawed knowledge base.
I can empathize with their user education team. As a fast-growing startup, they likely don’t have the resources to constantly audit documentation for consistency. For many enterprise companies, it's even a necessity to maintain conflicting articles for legacy customer integrations. This is the Achilles' heel of most current Retrieval Augmented Generation (RAG) implementations. Without a well-structured and clean knowledge base to draw from, they are simply search tools, ill-suited to find the one "true" answer a user is looking for.
The Search for a Single Source of Truth
This experience sent me searching for a better way. Could an LLM be prompted to actually reason about an answer’s validity before responding?
My research led me to a technique known as GraphRAG. The promise is powerful: instead of just searching documents, it allows a system to traverse a knowledge graph, essentially a map of how different data points are related. This provides a much richer, more reliable context for the LLM.
With a knowledge graph, a business manager could directly ask, “Show me all high-LTV customers in the CPG sector who have had a negative support interaction in the last 90 days,” and get a trustworthy answer. Better still, AI agents can build and maintain this graph from both structured and unstructured data, bypassing the need for massive, slow ETL (Extract, Transform, Load) pipelines.
Setting Up the System
This seemed like the answer, but I wanted to see it in action. I decided to build a simple demo to compare a GraphRAG system against a Standard RAG implementation head-to-head.
To make the test realistic, I first created the problem: two sample knowledgebase articles designed to simulate the real-world chaos of enterprise documentation.
[Legacy] Formatting API Requests with XML - A deprecated article that provides instructions to form an API request in XML
Formatting API Requests with JSON - The up-to-date documentation that uses JSON
The Standard RAG Approach
Standard RAG uses a technique called vector search. First a machine learning algorithm is run to generate embeddings, a numerical representation of the meaning of words or sentence “chunks”, from the source documents. You can think about the embeddings as the entries and page numbers in an index that identify where you can find a specific topic. When asked a question, the system will conduct a search for those document “chunks” that mostly match the topic of the question.
In our example, when asked about "API request formats," this system will correctly identify both the legacy XML article and the new JSON article as highly relevant to the original query. It then hands over the raw, conflicting text from both documents to the LLM, hoping for the best.
The GraphRAG Approach
The GraphRAG system is a little bit more sophisticated, deploying a two-step AI agent workforce to organize the knowledge contained in the source documents.
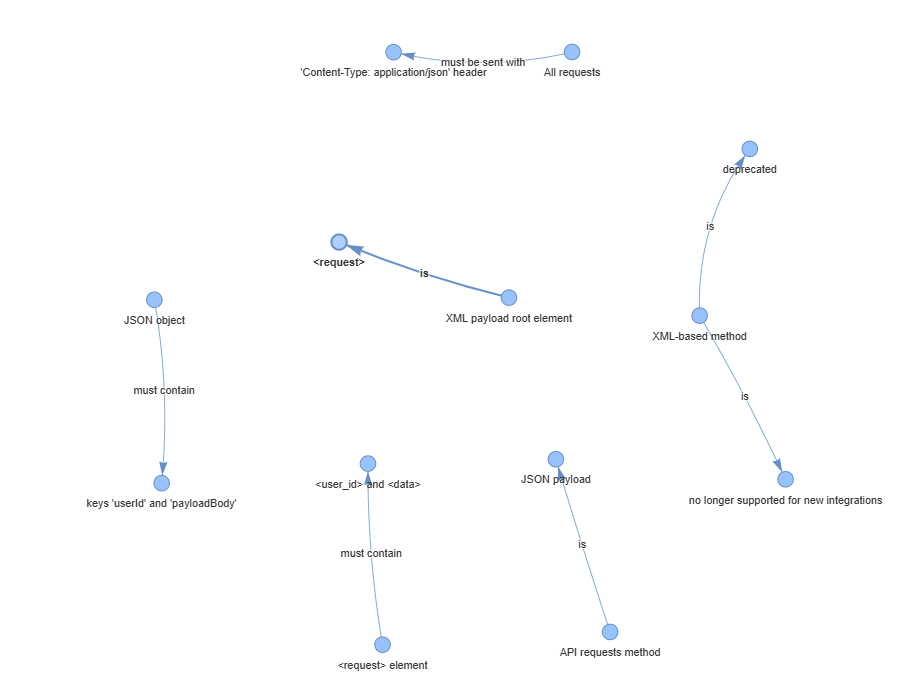
The Builder Agent: Extracts every factual statement it can find from the source documents. It then stores these in the knowledge graph as a structured “triple”. The theory of graph databases gets pretty technical, but one way to think about it is a “subject”, “predicate”, “object” format.
For example, “API request method”, “is”, “JSON payload”.The Critic Agent: Reviews all of the facts that were identified by the Builder agent. When it finds a conflict, like the request method being both ‘“JSON” and “XML”, it can use metadata such as the date_published, to make a decision to discard the older outdated fact. You could imagine being able to use other common metadata such as the feedback on a knowledgebase page to enable constant real-time updates to the chatbot’s understanding of “the truth”.

Feedback Widget on the Relevance AI Documentation Page
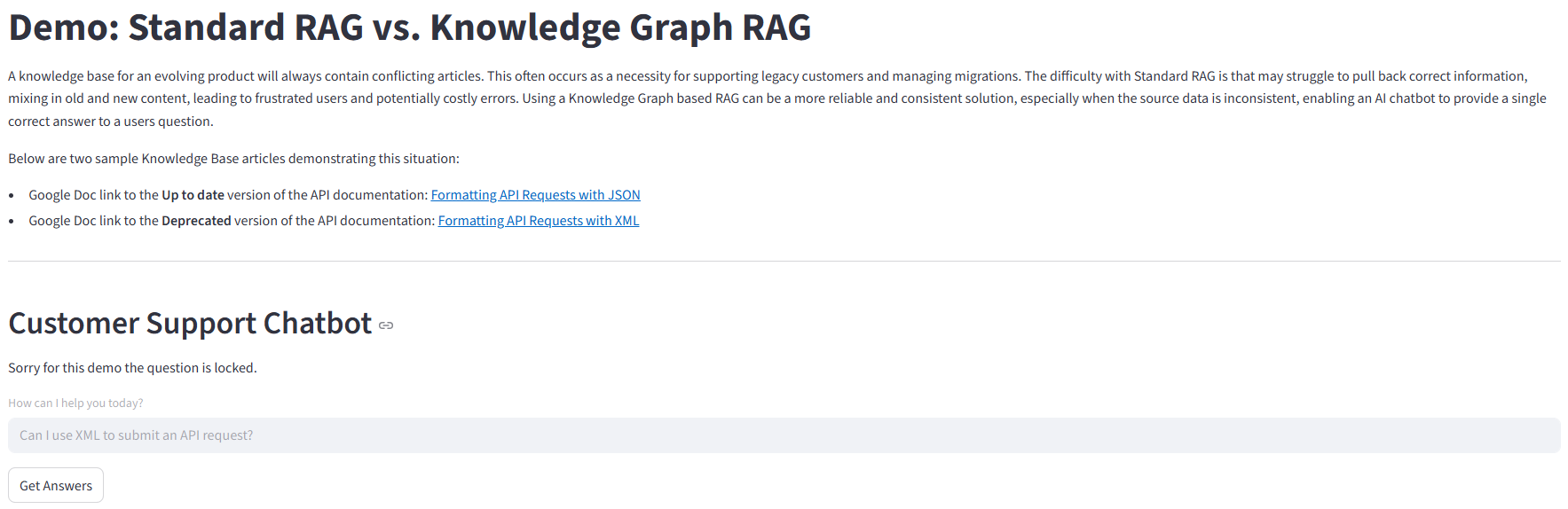
Back to our example, I used the same LLM (Gemini 2.0 Flash) to process the context provided by the two different search functions. The difference is in the context that is provided by the search function of the two different approaches. If we specifically ask the Standard RAG chatbot “Can I use XML to submit an API request?”, it will reply that this is possible, even though the method is deprecated. However, asking the GraphRAG chatbot the same question gets the clear response that XML is no longer supported and JSON is the correct payload for an API request.

Two answers to the question “Can I use XML to submit an API request?”
Visualizing the Knowledge Graph
To make the abstract knowledge graph concept more concrete, I used the pyvis Python library to generate a network visualization of the knowledge graph generated by the AI agents. In the graph you can literally see the network of validated facts that the system uses as its understanding of “truth”. We can also see the result of the critic agent specifically eliminating the deprecated fact that XML could be used to submit an API request.
From a Better Chatbot to a Unified Enterprise Knowledge Graph
The lesson here isn’t just about building a better chatbot. It’s about building a more responsive organization. The current friction in business comes from the time it takes to connect disparate data points to make a single, informed decision. By using AI agents to continuously maintain a central knowledge graph, we're not just retrieving answers faster; we're closing the gap between insight and action. The future of enterprise AI isn't a better search bar; it's a central nervous system that allows the business to sense, reason, and act in real time.
View my demo on the Streamlit Community Cloud!